如何自定义Kubernetes资源
目前最流行的微服务架构非Springboot+Kubernetes+Istio莫属, 然而随着越来越多的微服务被拆分出来, 不但Deploy过程boilerplate的配置越来越多, 且繁琐易错, 维护成本也逐渐增高, 那么是时候采用k8s提供的扩展自定义资源的方法, 将重复的template抽到后面, 从而简化Deploy配置的数量与复杂度.
Tips:一个基础的k8s微服务应该由几部分组成, 首先Deployment负责App的部署, Service负责端口的暴露, ServiceAccount负责赋予Pod相应的Identity, ServiceRole+RoleBinding负责api的访问权限控制, VirtualService负责路由
如果我们通过自定义资源的方式, 将每个微服务App的共有配置封装起来, 暴露出可变部分供各个应用配置, 如image, public/private api, mesh内访问权限等, 并设置mandatory/required的字段与validation pattern, 这样每一个App只需要一个配置文件, 就可以完成统一部署.
下面我们可以首先看一下k8s提供的扩展的两种方法.
- 通过Aggregated Apiserver
- 通过Custom Resource Defination
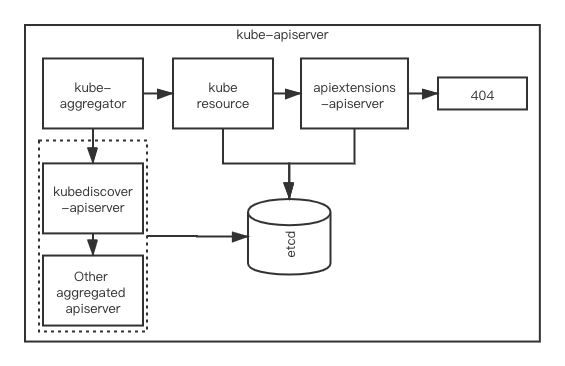
这两种最大的区别就是, 前者需要自己实现一个用户自定义的Apiserver, 而后者是被kube-apiserver内的extension apiserver module所处理.
二者都需要通过自定义Controller来处理资源的配置.
创建CRD
虽然看似AA的开放程度更高, 但实际上通过CRD来定义自定义资源更成熟且方便. 通过官方文档, 我们可以看到CRD的定义规则, 如下面我们定义的一个资源Beer:
1 | apiVersion: apiextensions.k8s.io/v1 |
这里我们添加了一个自定义字段beerName, 指定了pattern, 并且设置了spec与其下的beerName死required字段. 其余关键字可以查阅官方文档.
在apply该配置后, 通过kubectl get crd即可获得已经存在的资源.
1 | kubectl get crd |
有了CRD之后, 我们就可以apply自定义的资源了:
1 | apiVersion: weyoung.io/v1alpha1 |
这里大家可以试验一下required与pattern的作用是否生效.
这里有个比较关键的点, CRD中未声明的资源依旧可以被成功添加到Beer资源里, 并成功apply&configured, 但是不具备validation的效果, 这也可能是早期版本的crd把schema关键字换做validation的原因吧.
创建Controller
当我们实现了自己的CRD, 并且apply了根据CRD定义的自定义资源Beer后, 这仅仅是存在etcd的静态资源, 还需要controller来根据Beer的变化创建相应资源, 让Beer动起来.
首先可以先了解一下Controller的工作原理.
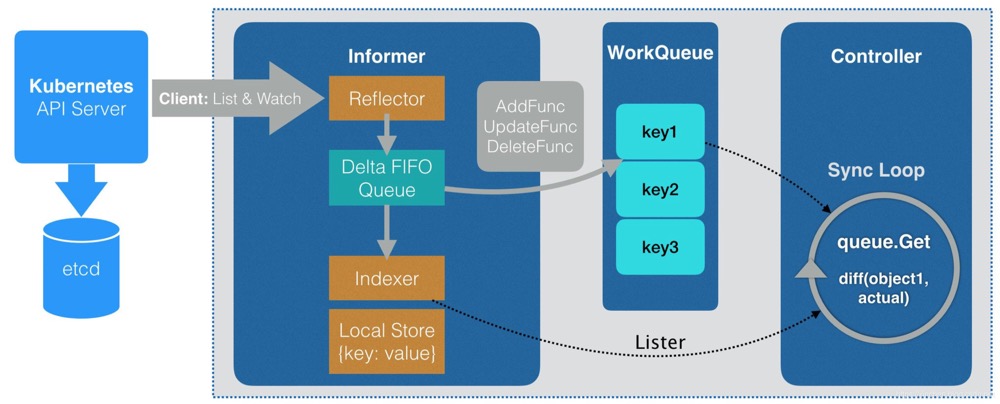
从图中可以看出, Informer模块内的Reflactor会监听k8sapi, 根据自己注册的资源类型, 轮询的将所有资源的最新状态存入队列, Indexer会对资源进行index, 生成key与namespace/name的映射关系.
通过Informer的监听方法, 可以从队列依次读取, 放进WorkQueue中供controller消费, 而controller可以通过Lister API由namespace/name获取到对应的自定义资源, 并做增删改查操作.
看似有很多模块在其中, 不过k8s已经帮我们实现了大部分(Informer, Lister等), 即它的client-go library. 我们只需要用对应的api来实现自己的controller部分就可以了.
具体的逻辑, k8s官方提供了一个sample-controller来供大家学习, 本人通过对这个sample的踩坑, 总结了一些需要注意的地方会在之后highlight出来.
总体来讲, 自定义自己的controller需要三个步骤:
- 定义资源Type与注册
- 生成Informer相应代码
- 编写与调用Controller
当然在这之前, 需要先添加依赖.
- apimachinery 负责client与k8sapi之间通信编解码等
- client-go 调用k8s cluster相关api
- code-generator 根据定义的type生成相关代码, 包括informer, client
这里需要注意的是依赖版本应该最新, 并且一致, 因为在尝试多次之后, 发现新老版本之间的变化非常大, 添加了很多新的module与功能, 而且如果不一致, 也会导致代码生成, 与k8sapi之间通信等各种的异常.
当我们通过go init custom-k8s-controller初始化新的module后, 可以添加最新依赖:
1
2
3go get apimachinery@master
go get client-go@master
go get code-generator@master
定义Type与注册
首先需要在工程目录创建一个存放自己api module的地方, 如api, 并在之下创建beercontroller, 放置我们自定义资源相关的代码, 版本号可以自己定义, v1/v1alphav1.
types.go
1 | package v1alpha1 |
这里定义了Beer的成员BeerName, 且有两行给代码生成器的注释也很关键, 不能缺失.
register.go
1 | ... |
这里省略了一些, 完整代码可参考官方sample. 这里主要的逻辑是将我们定义的资源注册上去, 当然由于还没有运行generator, AddKnownTypes会因为我们的Beer没有Deepcopy而报错.
生成代码
之前讲过需要实现一个完整的自定义k8s资源需要很多东西, 但实际上除了controller之外的都可以生成出来, 这里就使用到了code-generator里面的generate-groups.sh.
由于要使用该脚本, 这里我们可以添加vendor来管理我们的之前添加的依赖. 在工程的根目录输出git mod vendor来创建vendor目录, 这时所有之前添加过的依赖 (go.mod)都会出现在这个文件夹下供我们项目使用.
关于如何调用generator的逻辑可以参考官方sample, 这里我们需要给vendor整体(-R)赋予可执行权限, 否则在generate的过程会提示权限问题.
关于generate-groups.sh的使用需要注意的是它其中的2,3,4参数, 分别为输出目录, 输入目录(我们自定义资源的module所在的目录, 即之前创建的api文件夹), 自定义资源名:版本.
具体参数设置也可以参考:
1 | ../vendor/k8s.io/code-generator/generate-groups.sh \ |
在执行脚本过后, 它会在types.go旁生成deepcopy代码, 并会在我们指定的generated文件夹下生成informer, lister等代码.
编写与调用Controller
现在万事俱备只欠实现最后的自定义资源处理逻辑, 就是之前提到的controller.
首先我们需要定义controller的成员:
1 | type Controller struct { |
其中kubeclientset可以调用k8s的CRUD api, 例如创建更新deployment; beerclientset可以调用自定义资源的CRUD; deploymentsLister与beersLister可以通过namespace/name获得对应资源; workqueue用来同步与限流多个自定义资源处理worker; recorder用来publish在资源处理过程中的事件, 该事件可以在kubectl describe里面看到.
接着我们可以创建构造函数将clientset, informer传入构建自己的controller对象, 并通过informer的AddEventHandler添加监听, 将回调的beer资源通过indexer(cache)的MetaNamespaceKeyFunc方法转换为key, 加入workqueue队列.
当然有队列必然有死循环去读取这个队列, 这也是我们启动整个controller的入口, 我们需要从workqueue中pop交由下游处理, 在处理成功后调用forget方法清除queue, 否则会重新进行处理.
处理资源是我们controller的核心逻辑, 这里我们可以再次通过indexer(cache)通过key反转回namespace/name, 然后通过listers查找对应的资源, 比如beer或者deployment, 通过对比自定义资源与背后k8s资源的区别, 对k8s资源进行CRUD.
1 | func (c *Controller) syncHandler(key string) error { |
整个syncHanlder函数分为四个部分:
- 通过index做key->namespace/name
- 通过lister查找beer资源
- 如果不存在, 说明这是一次删除操作, 直接返回
- 通过lister获取deployment
- 如果不存在, 通过beer中相关字段创建对应的deployment, 或者其他k8s资源
- 否则, 说明资源已经存在, 则对比beer与实际资源的区别, 判断是否需要对相应的资源, 如deployment进行更新. 这里举例子
当然在整个过程中也可以通过recorder来广播event, 这样在apply自定义资源后, 可以获取一定信息, 方便查看或者debug问题原因.
controller完整的逻辑存在大量boilerplate的代码, 具体也可以参考官方的sample进行学习.
最后还有一点需要注意的是, 在我们创建并启动自己的controller时, 即本次custom-k8s-controller的入口main package内, 除了调用构造以及启动函数, 一定要记得传入的Informer需要调用Start进行启动, 否则无法获得资源变化的回调. 当然这里也涉及到需要传入一个stopSignal可以让监听中断, 这一个可以直接copy官方代码.
总结
k8s已经提供了一个非常详尽的demo来实现自定义资源并通过controller进行配置, 但是对于没有go开发经验, 有不少由于版本, 依赖, 权限造成的小问题, 希望文章中highlight的点能提供一定帮助~
最后通过不懈努力, 我们可以通过一个自定义的Beer资源来deploy pod了. 由于这条路的打通, 我们可以继续添加CRD的schema, 并在controller内进行解析, 简化deploy过程, 统一基于k8s的微服务基础架构. 比如对于任意一个通过Beer资源deploy的app, 我们都通过istio sidecar来做ingress/outgress, 对于image的完整仓库地址, 我们也在后面通过不同部署(apply)环境来组合不同的地址, 还有大量缺省值的公共配置, 都不需要再重复的写在多个yaml中了.